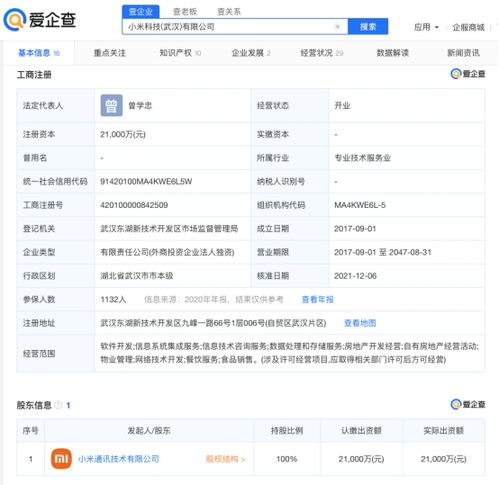
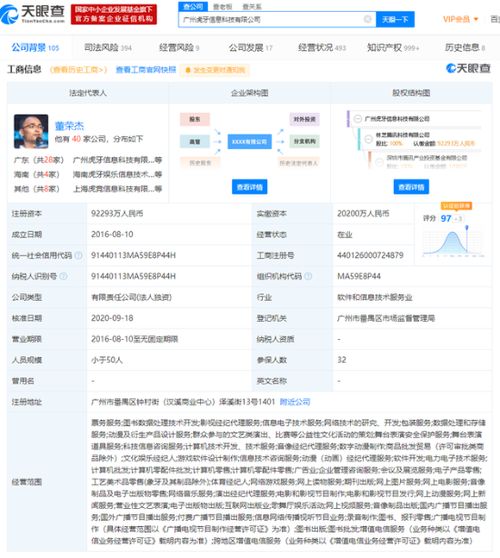
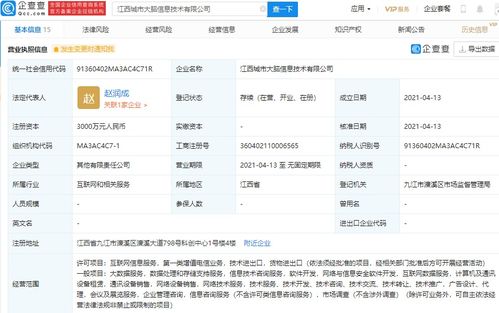
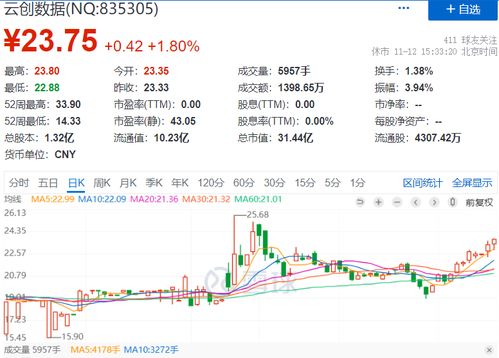
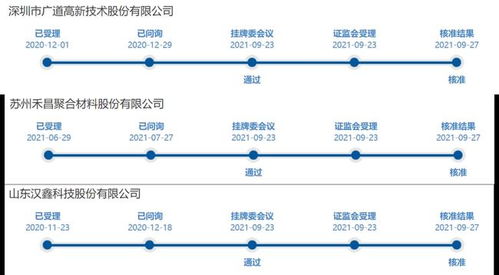
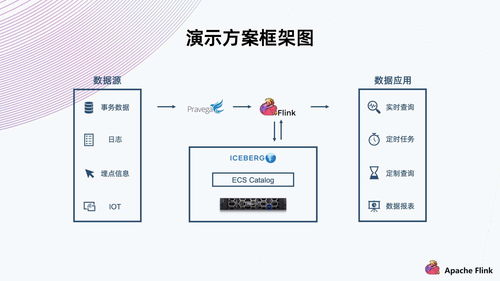
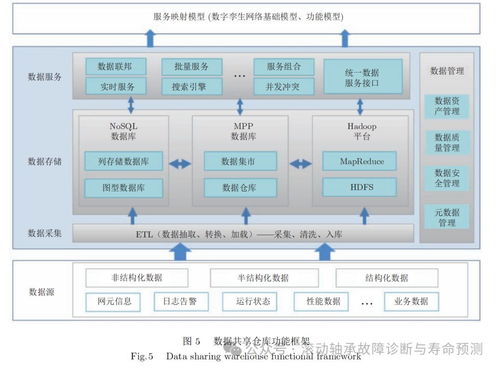
在數(shù)字化浪潮的推動下,數(shù)據(jù)中心、云服務(wù)及數(shù)據(jù)處理與存儲服務(wù)已成為現(xiàn)代信息社會的核心基礎(chǔ)設(shè)施。它們不僅承載著海量數(shù)據(jù)的存儲、處理與分析任務(wù),更是驅(qū)動企業(yè)創(chuàng)新、優(yōu)化業(yè)務(wù)流程的關(guān)鍵力量。
數(shù)據(jù)中心:數(shù)字世界的堅(jiān)實(shí)基石
數(shù)據(jù)中心作為集中存放計(jì)算設(shè)備與存儲系統(tǒng)的物理場所,其設(shè)計(jì)與管理直接關(guān)系到數(shù)據(jù)的安全性、可靠性與訪問效率。現(xiàn)代數(shù)據(jù)中心通常配備高效的冷卻系統(tǒng)、不間斷電源(UPS)與嚴(yán)密的安全防護(hù),確保硬件設(shè)備在最佳狀態(tài)下運(yùn)行。隨著綠色計(jì)算理念的普及,越來越多數(shù)據(jù)中心開始采用可再生能源與節(jié)能技術(shù),以降低碳足跡,實(shí)現(xiàn)可持續(xù)發(fā)展。
云服務(wù):靈活彈性的數(shù)字化引擎
云服務(wù)通過虛擬化技術(shù)將計(jì)算、存儲與網(wǎng)絡(luò)資源以服務(wù)形式交付給用戶,打破了傳統(tǒng)IT部署的地理與規(guī)模限制。無論是公有云、私有云還是混合云架構(gòu),企業(yè)均可按需獲取資源,快速響應(yīng)市場變化。云服務(wù)的優(yōu)勢在于其彈性伸縮能力——業(yè)務(wù)高峰時(shí)自動擴(kuò)容,需求下降時(shí)及時(shí)釋放資源,從而顯著降低成本并提升運(yùn)營靈活性。云服務(wù)商提供的AI分析工具與機(jī)器學(xué)習(xí)平臺,正幫助各行業(yè)從數(shù)據(jù)中挖掘深層價(jià)值,推動智能決策。
數(shù)據(jù)處理與存儲服務(wù):從信息到洞察的轉(zhuǎn)化器
數(shù)據(jù)處理與存儲服務(wù)是數(shù)據(jù)價(jià)值鏈中的核心環(huán)節(jié)。隨著大數(shù)據(jù)、物聯(lián)網(wǎng)與5G技術(shù)的普及,非結(jié)構(gòu)化數(shù)據(jù)呈爆炸式增長,對存儲系統(tǒng)的容量、速度與安全性提出了更高要求。分布式存儲、對象存儲及閃存陣列等新技術(shù)應(yīng)運(yùn)而生,不僅提升了數(shù)據(jù)讀寫效率,還通過冗余備份與加密機(jī)制保障數(shù)據(jù)完整與隱私。實(shí)時(shí)數(shù)據(jù)處理框架(如Apache Kafka、Spark)使得企業(yè)能夠即時(shí)分析流數(shù)據(jù),捕捉業(yè)務(wù)動態(tài),賦能精準(zhǔn)營銷、風(fēng)險(xiǎn)管控等場景。
未來展望:智能化與邊緣計(jì)算的融合
數(shù)據(jù)中心與云服務(wù)將進(jìn)一步向智能化與邊緣化演進(jìn)。人工智能將更深度融入基礎(chǔ)設(shè)施管理,實(shí)現(xiàn)故障預(yù)測、自動調(diào)優(yōu)與能效優(yōu)化;而邊緣計(jì)算則通過在數(shù)據(jù)產(chǎn)生源頭就近處理信息,減少傳輸延遲,滿足自動駕駛、工業(yè)物聯(lián)網(wǎng)等對實(shí)時(shí)性要求極高的應(yīng)用需求。
在這個(gè)以數(shù)據(jù)為驅(qū)動力的時(shí)代,數(shù)據(jù)中心、云服務(wù)及數(shù)據(jù)處理與存儲服務(wù)正如同一幅充滿活力的矢量插圖——背景是象征科技與創(chuàng)新的紫色,線條交織成穩(wěn)固而靈活的網(wǎng)絡(luò),持續(xù)支撐著全球數(shù)字經(jīng)濟(jì)的運(yùn)轉(zhuǎn)。只有不斷優(yōu)化這些基礎(chǔ)設(shè)施與服務(wù),我們才能充分釋放數(shù)據(jù)的潛力,迎接更加智能互聯(lián)的未來。